【论文速读】Can't Remember Details in Long Documents You Need Some R&R

简介
LLM在长文档QA中具有很大的价值,但容易遗漏上下文信息,本文提出R&R,结合重新提示reprompting,即在整个上下文中定期重复指令、达到提醒LLM其任务的目的,和上下文检索in-contexted retrieval,即先让LLM寻找与给定问题最相关的前k个段落,将这些段落用在第二次QA的prompt中。R&R有助于缩小相关上下文和指令之间的距离,因此较为有效地提高基于长文档的QA性能。
代码在casetext/r-and-r: Code for the "Long Context Needs Some R&R" paper.。
现有模型的问题
- 以ChatGPT和Claude为代表的模型能达到128k甚至200k的上下文长度,但是模型回答的质量会因输入的增加而有所下降。
lost in the middle效应:即使是16k的上下文,当相关上下文位于文档中间而不是开头和结尾时,基于文档的QA的LLM准确率会显著下降。
模型
提示模板分为三个顶层模块:首先,在<INSTRUCTIONS>之间封装问题和回答问题的指令。在<DOCUMENT>之间封装文档,在文档中每隔r个tokens就会重复指令,重复的指令封装在<INSTRUCTIONS_REMINDER>中。最后还会重复<INSTRUCTIONS>块的指令,确保它是 LLM 在生成响应之前看到的最后内容。图中的 逐字替换为指令。
因为R&R涉及到检索,所以文档会被切割成page,这里的page可以是一个句子、一个段落或者一个小节,封装在<PAGE {p}> . . . </PAGE {p}>中,p指的是page number。
重新提示
指令会在整个上下文文档中周期性地逐字重复。
作者的动机是他们观察到lost in the middle效应,认为模型回答问题的质量可能与文档中相关上下文和任务指令的距离有关。如果能够在相关上下文的前面重复指令,有可能提高模型回答问题的准确性。但是因为在长文档中无法预知上下文的位置,所以他们建议周期性地重复任务指令。
由于训练方式的原因,模型的注意力往往会集中在重复的标记上(重复出现多次的token),并且LLM还具有“迎合性”,利用这些特点,重新提示有利于保证LLM不会在长文档中忘记它的任务。
迎合性
“迎合性”(sycophancy)在大型语言模型(LLM)的上下文中指的是模型在生成文本时,可能以一种过度迎合或者尝试符合预期输出的方式来表达信息,这种方式可能并不总是准确或者客观。在LLM中,迎合性可能表现为模型过分倾向于生成讨好或者看似符合大众期望的回答,而非基于事实和数据的客观回答。例如,在回答开放式问题时,模型可能倾向于生成比较安全、不具争议的回答,以避免产生潜在的争议或不满。
在本文中,作者认为迎合性能帮助LLM更关注于输入的指令,从而能有更好地QA性能。
上下文检索
首先提示 LLM 从上下文文档中检索与问题最相关的段落,然后将检索到的段落汇总到一个简短的上下文文档中,然后在第二次 LLM 调用中进行短上下文 QA。
检索通常比QA简单,因为考虑的是召回率而不是准确率。
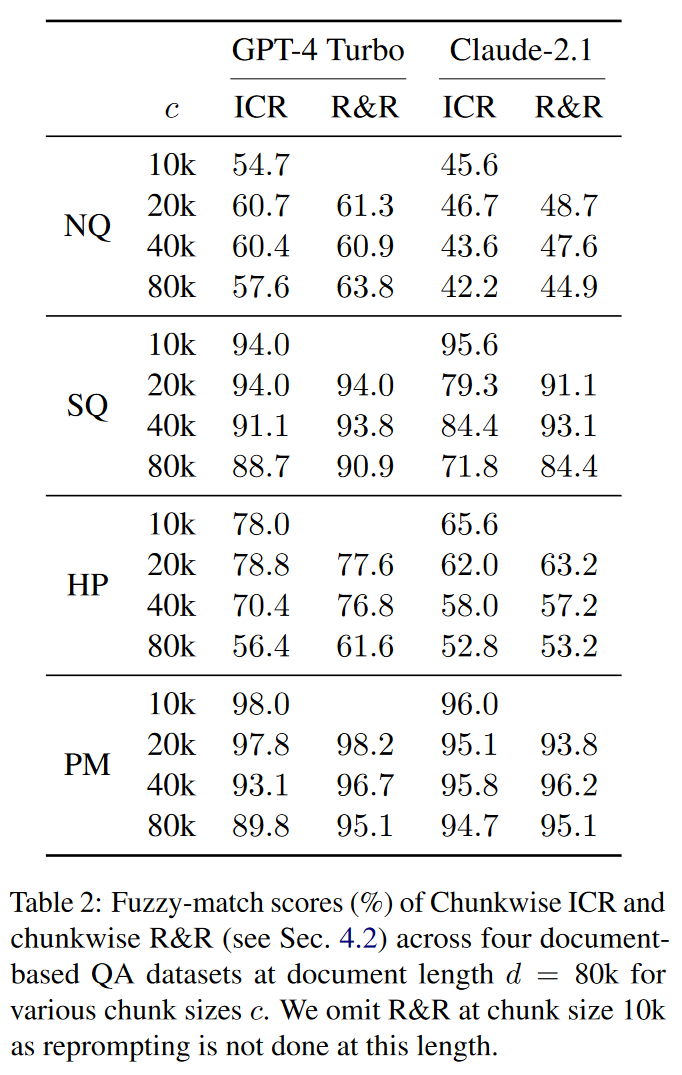
分块ICR
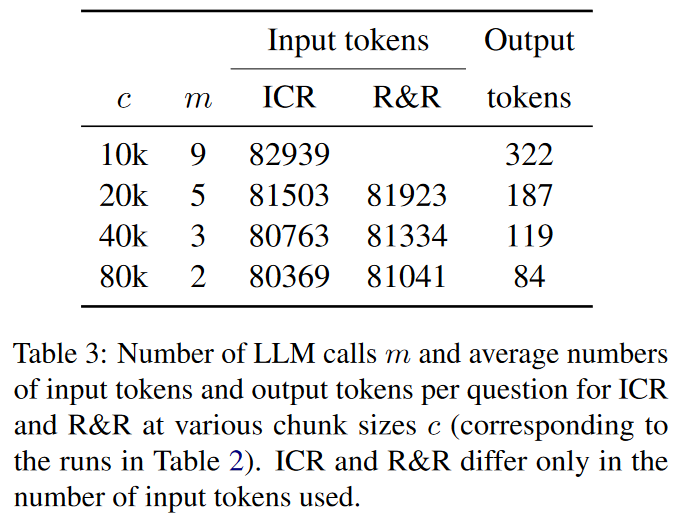
本文讨论的主要是长文档,所以为了结合重新提示和文本分块处理的优势,本文提出分块ICR。假设分成 个块,每个块运行一次检索,共有 个pages。如果分块分的很大,可以在块内引入Reminder模块。
相比传统的分块方法,这种分块的好处在于能够处理更大的块,减少LLM的调用次数,有利于缩减成本。
结合两种方法
在 ICR 的第一次调用中重新提示检索指令,即注入Reminder模块,然后在第二次LLM调用中进行QA。两次都使用上图的模板,但是第二次调用时因为已经没有长文本了,所以不会注入Reminder模块。
实验
数据集
NQ
NQ数据集:
- 来源:该数据集包含了向Google搜索引擎提交的历史查询问题以及由人工标注的答案。
- 版本和使用:本文使用的是Liu等人在2023年处理过的版本,该版本已公开。
对于每个问题,按以下步骤构建文档D:
- 段落包装:每个段落都用
<PAGE {p}>...</PAGE {p}>标签包装,其中{p}是相应的编号。 - 金标答案段落位置:在文档中,被注释为包含答案的“金标准”段落大约位于
xGPT-4 tokens处。 - 文档长度:整个文档大约长
dGPT-4 tokens。
实验设置
- 实验用的问题数量:从NQ中选择50个实例。
- 文档构建:每个问题的文档是通过将提供的段落以双换行符分隔列出来构建的。这些段落根据与问题的相关性进行排序。排序后,列表中存在一个包含答案的黄金段落,其余作为干扰段落
- 变量定义:
x(答案位置):金标答案段落在文档中的位置。d(文档长度):整个文档的长度。
- 变量调整:在实验中,
d取不同的10k的倍数,x从0到d,以10k为增量变化。
样本量计算公式
就是样本量
SQuAD
对于每个问题 Q,将其所附的上下文段落 P 视为 "黄金段落";A 是包含 P 的维基百科文章,将 Q 的干扰段落视为数据集中,A以外的其他段落。给定答案位置 x 和文档长度 d,然后我们为问题 Q 创建上下文文档 D,过程类似于NQ。
HotPotQA
多跳问答数据集,需要多个上下文。对于问题P,黄金段落有多个,与问题无关的段落视为干扰段落。构建文档D时,每隔n个干扰段落插入一个黄金段落。所以,在本数据集中,x(答案位置)并不适用,因为答案均匀分布在整个文档中,N取250。
PubMed
PubMed数据集是一个基于生物医学论文摘要构建的合成问答(QA)数据集。这些摘要通过PubMed搜索引擎获取,具体涉及2024年发布并被加入PubMed索引的文档。摘要长度在150到200个tokens,时间是2024年的新文献(避免数据泄露)。
问答对生成:使用GPT-4 Turbo为每个选定的摘要生成一个问题。这个问题的答案必须完全依赖于给定的摘要,不能包含任何额外的信息。答案形式为单词或短语。确保每个问题-答案对即使在更长文档中作为单独一段出现时也能保持逻辑上的通顺,因此排除了像“摘要的第一个词是什么?”这类元问题(metaquestions)。
文档构建:与前NQ数据集类似,只有一个摘要段落包含答案,其余都是干扰段落。
评估方法
使用模糊匹配 fuzzy match 评估。数据集中的答案都是短序列的关键词,不是开放式问题。将LLM预测的答案A′与真实答案A进行比较,如果A中的所有唯一词也出现在A′中,则返回1,反之返回(去除非字母数字非空格字符和大小写后)0。对于整个数据集报告的模糊匹配分数是数据集中所有N个样本(包括问题和答案两个位置)的平均值。
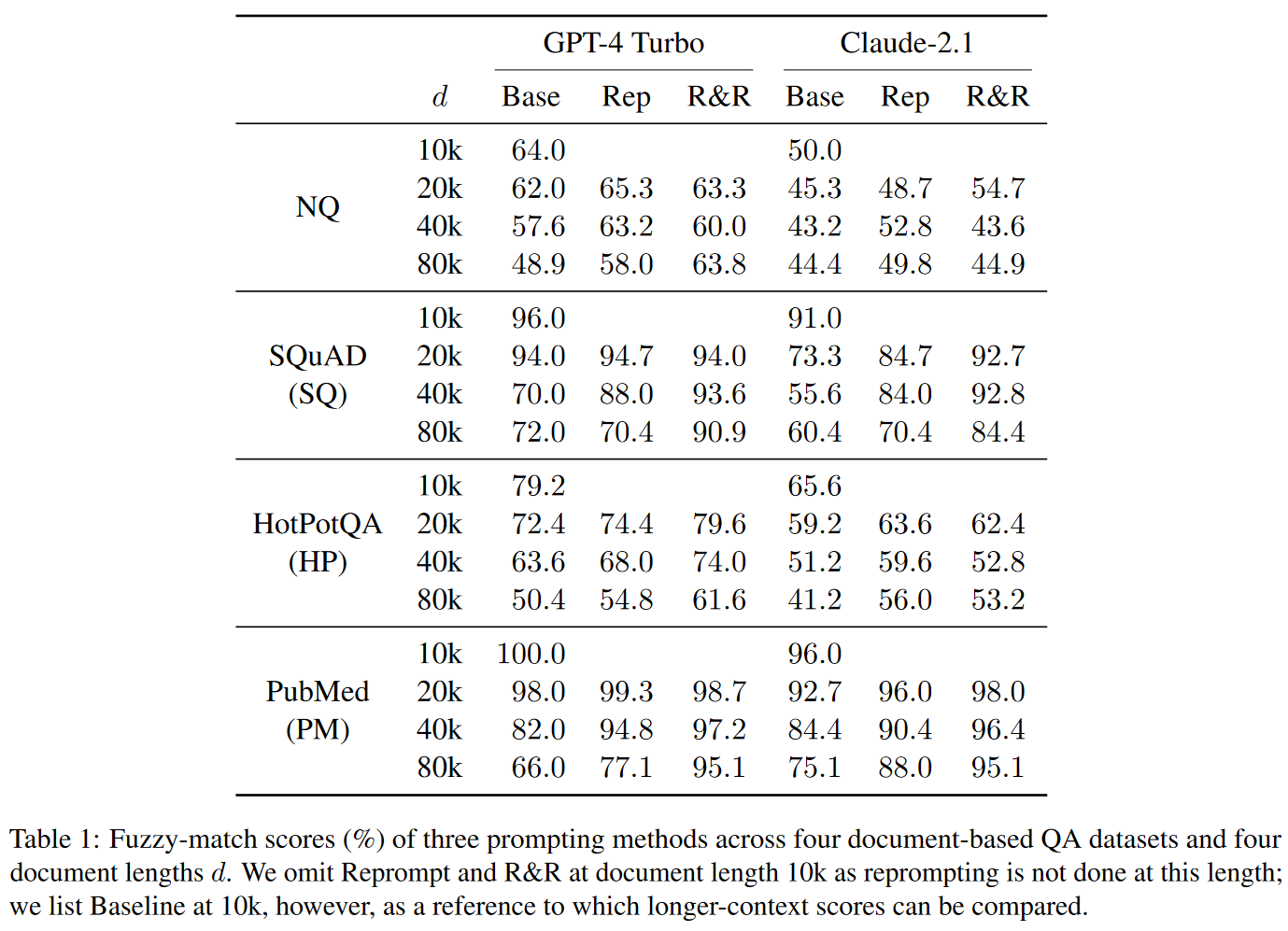
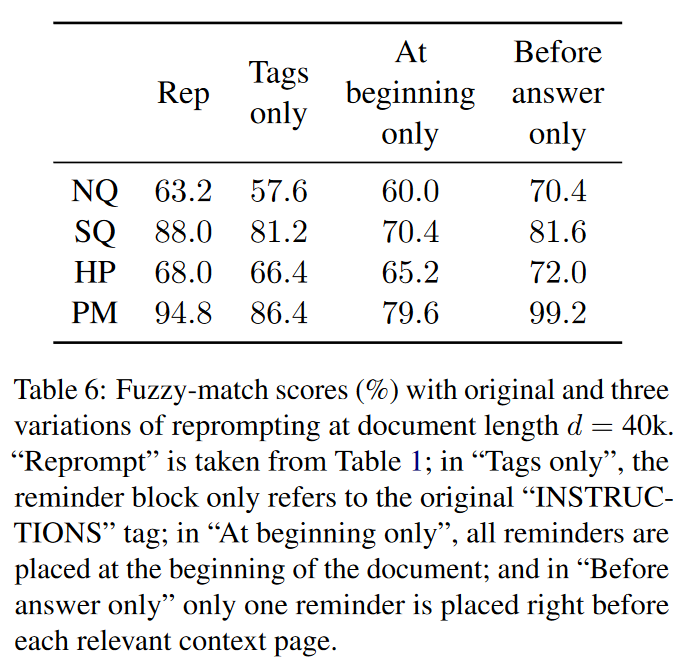
实验结果