【论文速读】Efficient Classification of Long Documents via State-Space Models
简介
Transformer由于二次时间复杂度和长度外推能力有限,难以高效处理长文档,本文通过实验证明SSM模型在长文档分类任务中更为有效。本文还提出了SSM-pooler模型,在性能相当的情况下,效率高出36%。即使在40%的极端场景下,SSM-pooler对输入噪声也表现出更高的鲁棒性。
Transformer解决现有问题的思路
- 将长文本截断到预定义的长度,比如4096个tokens,但这样会丢失一些重要信息
- 减少self-attention的计算开销,比如稀疏注意力
- 在原始Transformer上进行改进,比如对长文本分块进行编码,聚合所有块表示,在处理这个块表示
- 改进位置嵌入
模型
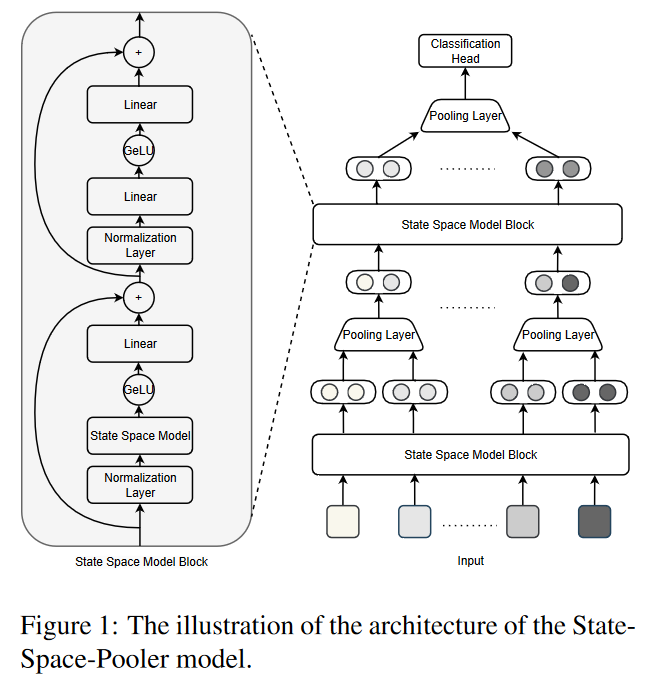
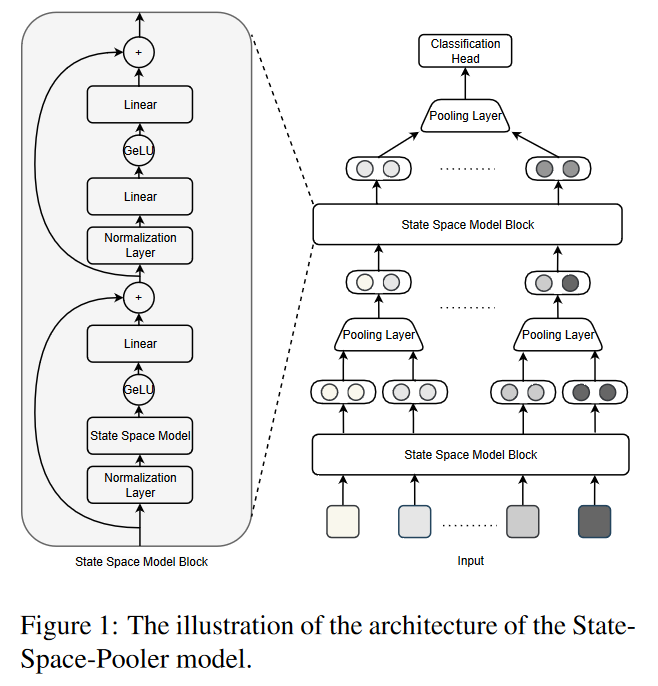
模型图如下,左侧是原始的SSM模型,右边是增加了池化层后的SSM-pooler模型
SSM
SSM把一维连续输入信号映射到一个N维隐藏状态,然后将这个隐藏状态映射到一维输出。这个过程定义如下:
其中,是可以训练的参数。在这里,表示状态的导数,表示状态随时间的变化率。
文本等离散序列可以被看作是从连续信号中以步长采样得到的离散化数据。当应用到离散数据时,状态空间模型(SSM)以递归方式表示如下:
其中,是对应于离散模型的参数。
通过将SSM重写为线性卷积的形式,就可以加速加速编码过程:
其中, 是长度为 的向量,定义为SSM的卷积核。对于输入序列,输出序列可以通过卷积快速计算,时间复杂度为,通过快速傅里叶变换(FFT)实现。
SSM-pooler
对系统架构进行修改,即逐步减少较深层的输入长度,从原始输入层向最终表示层逐步构建表示层。通过在每个 SSM 块之间插入一个最大池化层,每一层的模型都能自动提取附近输入之间的重要信息,并将输入长度减少到上一层的一半,从而进一步加快了训练和推理的速度。
在计算最后一层的平均值后,将其输入到具有 softmax 或 sigmoid 函数的全连接密集层,以分别输出多类或多标签问题的预测概率。
实验
数据集
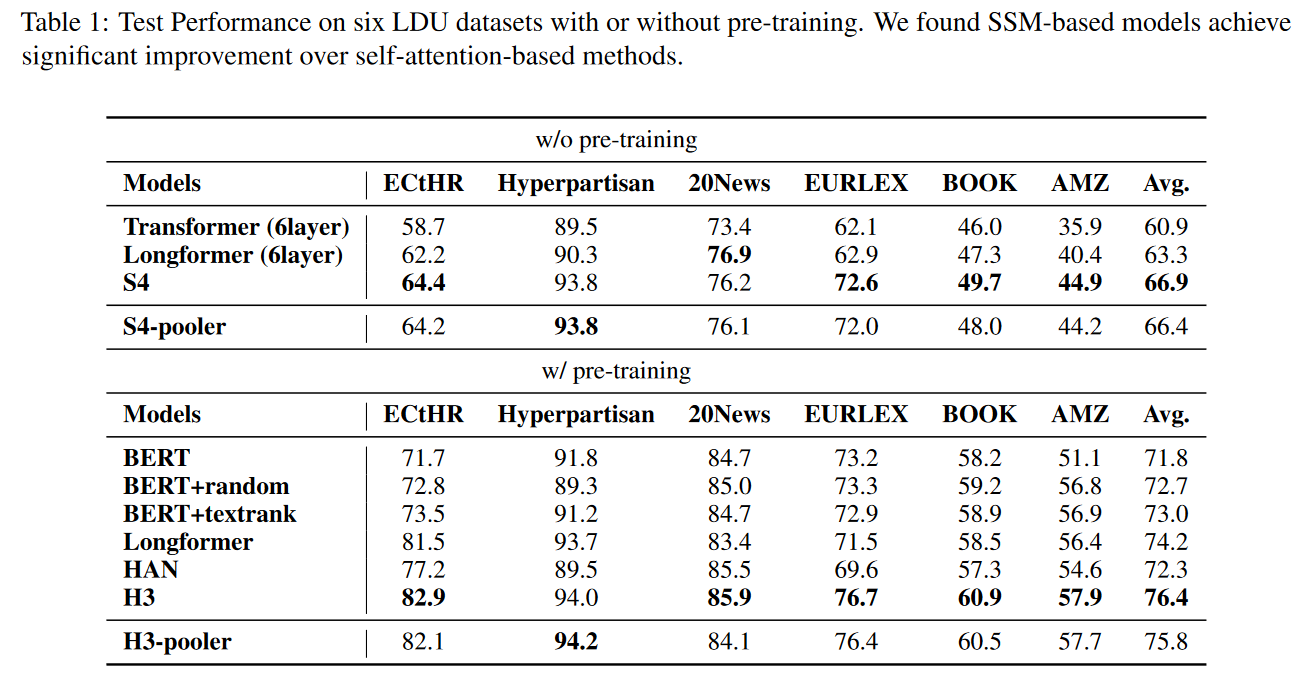
评估了六个常用长文本分类数据集,包括Book、ECtHR、Hyperpartisan、20News、EURLEX和Amazon product reviews (AMZ)。对于 AMZ 数据集,从图书类别中随机抽取了字数超过 2048 字的评论。
Baselines
使用6层S4、S4-pooler、Transformer和Longformer模型进行比较。对于带有预训练的模型,使用带有截断输入长度的 BERT-base 及其两个变体 BERT-random 和 BERT-textrank,以及一个稀疏注意力模型 Longformer 和一个分层变换器模型 ToBERT。结论如下: