【论文速读】Long-Context Language Modeling with Parallel Context Encoding
简介
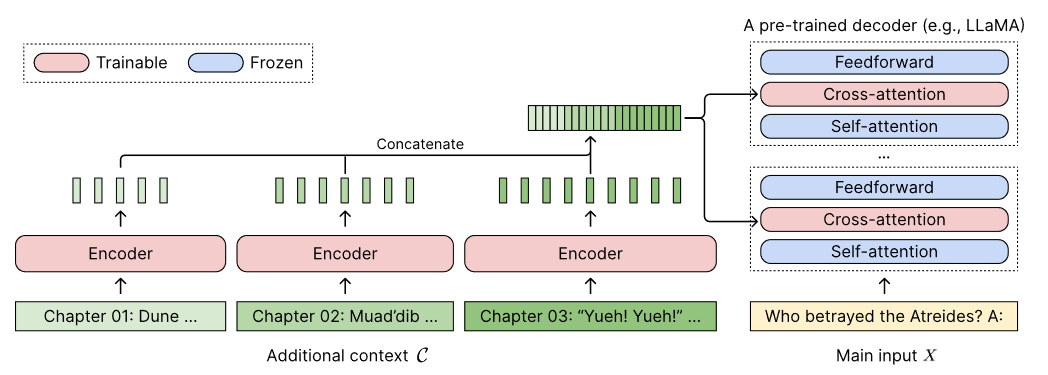
因为Transformer的二次时间复杂度和位置编码的扩展性有限,上下文窗口比较小,本文提出CEPE(Context Expansion with parallel encoding)并行编码上下文扩展,采用小新编码器逐块(chunk)处理输入文本,使冻结的解码器能通过cross-attention利用更长的上下文,可以使用在任何只有加码器的llm上,并且无需微调。
代码在CEPE: Preprint: Long-Context Language Modeling with Parallel Encodings。
优点
- 长度泛化:因为采用分块编码,所以不需要扩展位置编码的长度,因此可以避免一些位置编码插值过密导致的信息丢失问题
- 效率:因为cross-attention只关注encoder最后一层的表征,所以内存消耗比纯解码器LLM小(纯解码器LLM需要缓存每一层中每个token的key、value对
- 训练成本低:不需要完全微调,训练时,解码器LLM是冻结的,只调整encoder和cross-attention层
模型
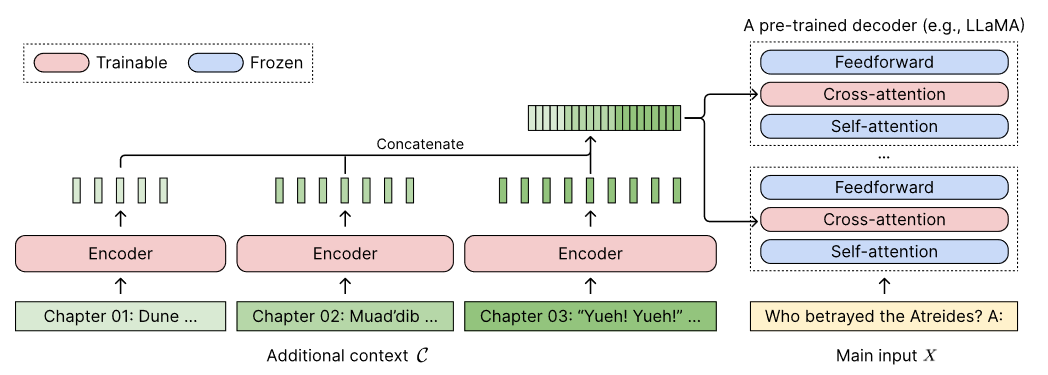
主要改进:
- 使用很多小型编码器,对长上下文进行分块编码
- 在解码器中的每一层的self-attention和feed-forward层之间插入一个cross-attention模块,以便注意encoder的信息
Notation
给定一个包含 个tokens的输入上下文 ,将前 个tokens视为附加上下文 additional context ,剩下的 个tokens即 视为主输入 ,对附加上下文分块,则 ,每一个分块都包含了原始长文档的一个小分段。用 表示隐藏维度为 的encoder,用 表示隐藏维度为 的纯解码器LLM。
编码各个分块
使用可训练的编码器 逐块编码附加上下文 ,即
是从可训练的编码器 中生成的基于单个令牌(对每个词进行处理,不是对句子或者段落)的最后一层隐藏状态。可训练的编码器 是双向的,比单向编码器能获取到更多信息。
然后对各个分块的隐藏状态进行合并操作
编码器是如何工作的
以Bert模型的编码器为例,给出一个例句“Augmenting LMs with retrieval has been useful in many applications, such as open-domain question answering.”,处理过程大致如下:
- 分词(Tokenization):首先,这段文本将通过分词器进行分词处理。BERT使用WordPiece分词算法,将文本分解为较小的片段或“令牌”。例如,“Augmenting”可能被分为“Augment”和“##ing”,这里“##”表示它是一个单词内部的分割。
- 添加特殊标记:在BERT中,通常会在句子的开始添加一个特殊的[CLS]标记,句子的结束添加一个[SEP]标记。因此,处理后的令牌序列可能看起来像这样:
[CLS] Augment ##ing LMs with retrieval has been useful in many applications , such as open - domain question answering . [SEP](中间的单词没有分词) - 映射到ID:每个令牌将被转换成一个唯一的数字ID,这些ID对应于BERT预训练模型的词汇表。
- 位置编码:为了保持单词在句子中的位置信息,BERT还会为每个令牌添加位置编码。
- 通过BERT编码器:将令牌的ID和位置编码输入BERT模型。模型包含多个相互作用的Transformer层。每一层都执行自注意力操作并产生新的隐藏状态,这些隐藏状态是输入令牌的更复杂的表示。
- 输出隐藏状态:对于每个输入令牌,BERT的最后一层将输出一个隐藏状态向量。这些向量是高维的,每个向量的维度取决于模型的具体配置(例如,BERT-Base模型的隐藏状态大小为768维)。这些隐藏状态向量包含了关于原始文本及其上下文的丰富信息,可以被用于多种下游NLP任务。
所以,对于每个块 ,输出隐藏状态的大小是 ,注意此处是解码器的隐藏状态的维度大小,而不是编码器的隐藏状态的维度大小。经过聚合操作,总隐藏状态的大小就是 ,因为 是附加上下文 所包含的 tokens 的数量。
cross-attention模块中的key和value投影矩阵会将 维的 转为 维的嵌入。
为什么维度大小是解码器的隐藏状态的维度大小
本人认为,可能是后续cross-attention进行训练、LLM进行推理时,用的向量的维度都是 ,所以此处直接编码成解码器的隐藏状态的维度大小比较好?这样就不需要再进行一次转换。
Cross-attention
在每个decoder层的self-attention层和前馈网络层中插入cross-attention模块,将 作为key和value,将输入 的隐藏状态作为 query
效率
因为 体积更小,而且采用并行编码,所以能避免Transformer注意力的二次时间复杂度。此外,因为没有缓存 个key和value对( 为解码器层数),只需要缓存 和 个键值对,CEPE能大幅减少消耗,因为 且 。原Transformer的内存复杂度为 ,CEPE为 。实际中,可以节省内存至原来的 。
实验
数据
使用 RedPajama 数据集,分成两部分
- 聚合所有领域的文档形成训练序列
- 保留数据集中 ArXiv 和 Books 领域的、超过8192个tokens的数据集,并且在文档范围内采样序列
训练时, 为 ,这样有利于泛化
训练
使用 LLAMA2 7B 作为 ,并且插入cross-attention层,增加 435M 的双向编码器 作为编码器,这个编码器在CEPE中会产生1.8B的参数。
热身训练
冻结解码器模型的原始权重,只训练添加的交叉注意层。热身训练的目的是教会 从 中获取信息,对于每个位置 ,根据 和 生成 ,所以编码器和解码器是共享相同的输入的。这个阶段使用约131M个tokens。
标准训练
每个序列有8192个tokens,使用最后4096个tokens作为输入,将前4096个tokens分成16块上下文,每块上下文具有256个tokens,训练20B个tokens。因为标准训练时冻结了解码器,所以一张A100即可完成这个过程,比直接用8192的序列长度去训练解码器,显存消耗显著下降
知识蒸馏
把方法扩展到指令调整模型(instruction-tuned models),由于缺乏高质量的教学数据,直接通过微调将这些模型扩展到更长的语境窗口具有挑战性。
因此,作者提出了 CEPED,它使用辅助蒸馏损失来鼓励 和交叉注意层学习已经经过指令调整的 的能力。原始的 充当老师,CEPED模型充当学生,使用4096个tokens的输入上下文 CONCAT(C, X)。首先将CONCAT(C, X)输入 ,并将 X 的对数保存为教师对数。在训练过程中,C 和 X 分别作为 和 的输入,将 X 的输出对数与相应的教师对数之间的 KL 发散以及交叉熵损失降到最低。
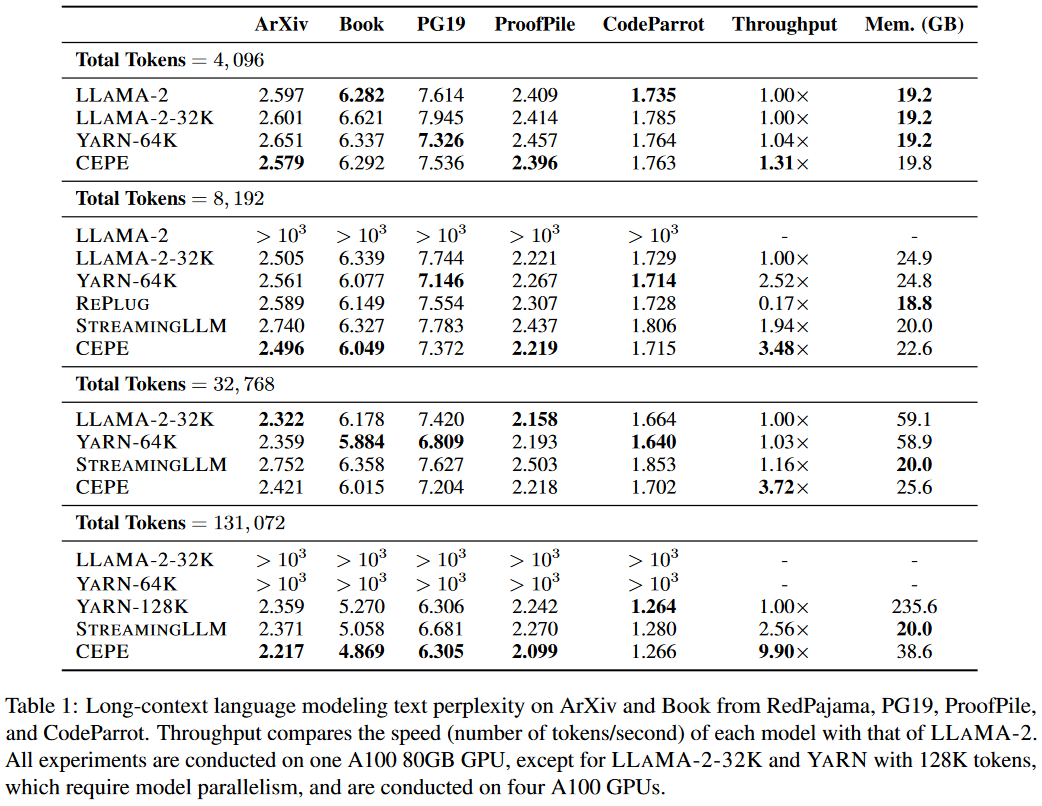
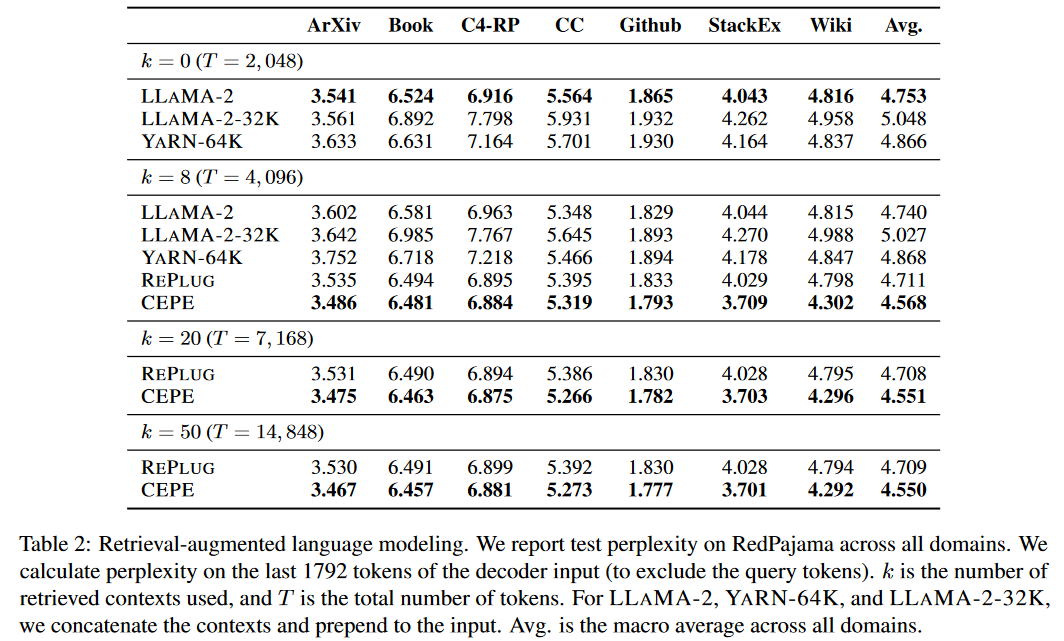
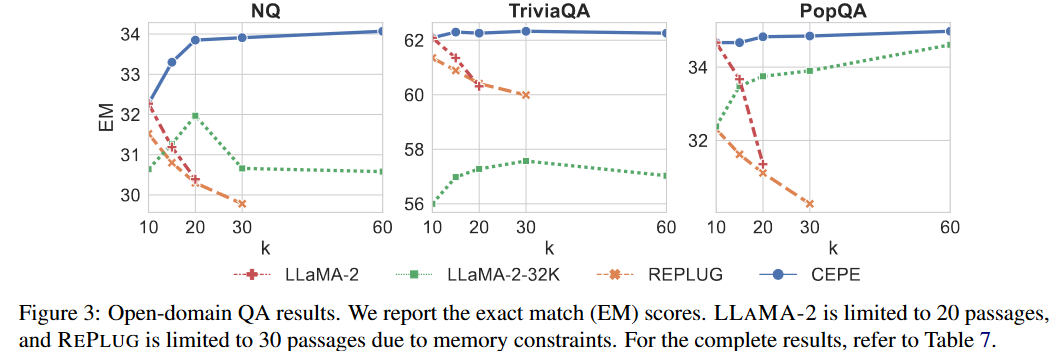
实验效果
困惑度、显存、推理速度对比
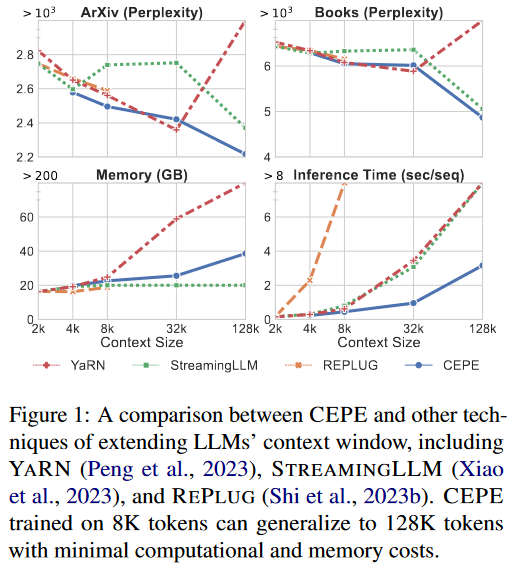
不同模型、上下文窗口长度、困惑度、显存、推理速度对比